
c&p
一. 标准函数库
1. 时间
类型对比:
-
定义:
time_t是当天日期时间,clock_t是程序运行时间。 -
长度没区别
time_t : typedef long time_t
clock_t : typedef *long* *clock_t*
C experts
2.3 重载冗杂
sizeof并不是一个函数,而是一个操作符。
- 操作数是变量:不必加括号。
sizeof *p获取p指针指向对象的字节数 - 操作数是类型:必须加括号。
sizeof(int) *p。
这里含义是什么? 强制转换int型之后 sizeof?还是int长度乘以p? 实践:是后者。
1 | int main () { char a = '5'; int *p = &a; int q = sizeof(int) * p; printf("%d", q); return 0; } |
apue
1. 线程
线程同步
多线程共享相同内存,需要保证每个线程看到一致的内容。
有线程写就可能触发数据不一致,所以读写要加锁。
互斥量
pthread_mutex_t 互斥量可以嵌入数据结构、也可以全局变量。
pthread_mutex_init , pthread_mutex_destory , pthread_mutex_lock, pthread_mutex_trylock, pthread_mutex_unlock
条件变量
条件变量运行线程以无竞争的方式等待条件发生。
条件变量由互斥量保护 计算更新。
条件变量初始化和销毁:pthread_cond_init, pthread_cond_destory
等待条件状态:pthread_cond_wait(mutex, cond) 线程把锁住的互斥量传入, 函数会把该线程放到等待条件的线程列表上,并对互斥量解锁。函数返回时,互斥量再次锁住。
通知条件状态: 在状态改变后通知。
pthread_cond_signal(cond) 会唤醒至少一个等待该条件的线程。
pthread_cond_broadcast(cond) 唤醒所有等待线程
案例:消息入队时候队列需锁住, 但处理消息时无需锁住,只需等待某一条件发生。
对比互斥量而言,等待条件更灵活。
1 | # |
12.线程控制
同步属性:
互斥量属性:
默认属性初始化:pthread_mutex_t qlock = PTHREAD_MUTEX_INITIALIZER;, 或者pthread_mutex_init(&mutex, NULL)
非默认属性:pthread_mutexattr_init(attr) . pthread_mutex_init(&mutex, &attr) 先初始化设置互斥量属性,再用属性来初始化互斥量
- 类型属性
PTHREAD_MUTEX_RECURSIVE: 互斥量通过计数来加锁解锁。
进程关系
会话
建立一个新会话setsid()
- 如果进程是进程组组长,出错。 一般先调用fork,然后使父进程终止。子进程即继承进程组ID,但不是进程组组长。
- 如果进程不是进程组组长,则创建新会话成功。具体地:
- 该进程成为会话首进程。
- 该进程成为一个新进程组的组长。
- 该进程没有控制终端。
守护进程
系统守护进程
cron:定期日期实践执行。
初始化守护进程
- 创建一个会话:(a)新进程会直接成为会话的首进程。(b)成为一个新进程组的组长进程。(c)没有控制终端
1 | if ((pid = fork()) < 0) |
- 信号处理 :确保后续守护进程不会持有终端,且不受控制终端影响。
1 | sa.sa_handler = SIG_IGN; |
SIGHUP信号会在终端关闭时候发送给进程,这里SIG_IGN忽略处理,使得终端关闭不影响进程运行。
sigemptyset(&sa.sa_mask); 表明处理SIGHUP信号时不会阻塞其他信号。
1 | if ((pid = fork()) < 0) { |
第一次exit, fork 守护进程仍然可能重新获得终端, 第二次exit、fork保证进程不会成为会话首进程,确保一定不会获得终端
- 文件描述符 attach 到
/dev/null:守护进程不与终端输入输出交互。
1 | fd0 = open("/dev/null", O_RDWR); |
出错记录
大多数守护进程使用syslog记录日志消息。syslogd守护进程处理日志消息。syslog不生产数据报,用户进程或守护进程需要按照日志消息格式发送到套接字。
产生日志消息的方法:
(1)大多数守护进程通过syslog(3)函数产生日志消息,消息会被发送到UNIX域数据报套接字 /dev/log 上。
(2)任何用户进程可以将日志消息发送到网络套接字udp端口514。
用法:
- 设置日志类型, 位屏蔽
1 | openlog("process name", LOG_PID, LOG_LPR); |
- 记录日志消息
1 | syslog(LOG_ERR, "open error for %s: %m", filename); |
syslog 为方法一,与/dev/log套接字通信。
进程根目录为/ , 如果chroot(newroot)改变进程根目录,那么根路径从newroot开始
查看syslog,tail -f /var/log/syslog
单实例守护进程
如网络服务,需要任一时刻只有一个实例运行,避免发生资源冲突,如端口冲突。
实现方法:任一时刻只运行守护进程一个副本。 通过文件和记录锁机制来实现,每个守护进程有一个固定名字的文件,只允许这个文件有一个写锁,创建写锁失败,即表示不能不能创建守护进程。在守护进程终止时,会自动清理锁。
案例:创建守护进程时调用,试图创建一个文件,将pid写入。如果返回1,表明文件有锁,创建失败。
1 | # |
ftruncate(fd, 0); 将文件长度截断为0,清空文件内容。
errno == EACCES || errno == EAGAIN ;表示权限不足或者操作失败。
LOCKMODE (S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH) : 文件所有者读写权限、所属组读权限、其他用户读权限。
守护进程的惯例
- 如果守护进程使用文件锁,文件格式为
/var/run/守护进程name.pid, 如:/var/run/crond.pid内容为pid - 如果守护进程支持配置,文件格式为
/etc/守护进程name.conf - 守护进程可以用命令行启动。通常由
/etc/init.d/*系统初始化脚本初始启动,当守护进程终止时,应当自动重启,自动重启通过/etc/inittab包括respawn记录项,init就会自动重启守护进程。 - 重读配置文件方法:kill重启。另外方法,守护进程去捕获SIGHUP信号,因为没有控制终端,可以安全重复自己使用。
单线程守护进程:
获取当前文件名
1 | char *cmd; |
设置SIGHUP信号处理为默认,且不阻塞任何信号。
1 | sa.sa_handler = SIG_DFL; |
主线程阻塞所有信号,专注运行, 创建一个线程来处理信号。
1 | sigfillset(&mask); |
处理信号的线程:
1 | void *thr_fn(void *arg) |
sigwait:设置要等待的阻塞信号,与pthread_sigmask一致,表示等待所有被阻塞的信号。线程挂起,直到其中有被阻塞信号触发。
SIGTERM和SIGHUP默认动作都是终止线程,这里作为替代,不会终止线程。
常见守护进程
/usr/sbin/cron:这是定时任务调度器cron的进程。/usr/sbin/rsyslogd:这是系统日志服务rsyslogd的进程,它负责收集、处理和转发系统日志。/usr/lib/snapd/snapd:这是snapd守护进程,它是 Snap 包管理器的后台服务。/usr/sbin/xinetd:这是xinetd守护进程,它是一个基于 TCP Wrappers 的超级服务器,用于管理和启动其他网络服务。/usr/libexec/packagekitd:这是 PackageKit 守护进程,它是一个软件包管理服务,用于管理软件包的安装、更新等操作。/usr/libexec/polkitd:这是 PolicyKit 守护进程,它是一个系统权限管理服务,用于控制用户对系统资源的访问权限。
场景
- 守护进程查看是否有登录名。A:没有。因为没有控制终端。
1 | # |
高级IO
非阻塞IO
系统调用分为两类:低速系统调用和其他。低速系统调用是可能使进程永远阻塞。
并不是所有有磁盘IO相关的系统调用都是低速系统调用、都会阻塞。
非阻塞IO可以发出open、read、write这样的操作,并永远不阻塞。
对于一个文件描述符,可以指定其为非阻塞IO。
(1)调用open获得描述符,指定O_NONBLOCK标志。
open()
(2)已经打开的描述符,调用fcntl,打开O_NONBLOCK标志。
实例:如果被阻塞,立即返回。
1 | set_fl(fd, O_NONBLOCK); |
记录锁
多个人同时编辑一个文件,结果如何?
一般的,会取决于写该文件的最后一个进程。但是对于数据库,只能一个写。
记录锁:一个进程读或者修改文件某个区域,阻止其他进程同时修改这一区域。
1 | int fcntl(int fd, int cmd, struct flock *ptr); |
cmd:F_GETLK测试是否能建立一把锁(很少用)。F_SETLK加锁。F_SETLKW阻塞式加锁,即如果文件已经加锁,该进程就会休眠阻塞。flock: 表明锁类型(共享读锁、独占写锁、解锁一个区域)。加解锁区域。相关进程PID。
加解锁时,会组合或分裂区域。
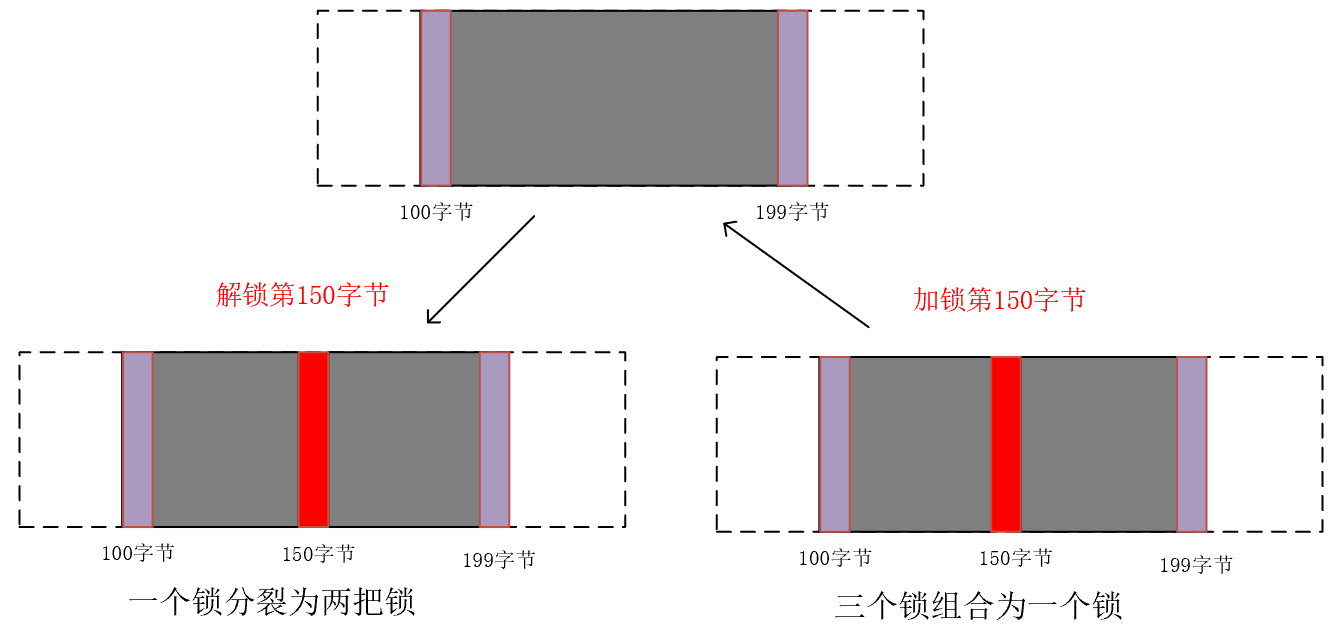
案例:请求和释放一把锁:
1 | # |
IO多路转接

1 | while ((n = read(STDIN_FILENO, buf, BUFSIZ)) > 0) |
需求:从两个描述符读, 可能会阻塞在一个读IO上,导致另外的描述符也不能读。也不知道到底哪个输入会得到数据
IO多路转接:构造一个感兴趣的描述符表,调用一个函数,直到其中一个描述符已经准备好,该函数才返回。 poll , select, pselect , 返回后 进程会得知哪些描述符已经准备好。 然后就可以正确调用IO read , write
select
int select(maxfdp1, readfds, writefds, exceptfds, time)
maxfdp1表示三个描述符集最大值加1.readfds, writefds, exceptfds表示感兴趣的 读写、异常状态的描述符集。 每个描述符为一位。
1 | fd_set rset; |
time表示愿意等待的时间- 返回值: -1表示出错, 0表示描述符都没有准备好,大于0为准备好的描述符个数
- “准备好”含义:读集合中读不会阻塞,写集合写不会阻塞,
sql4
sqllite简单版
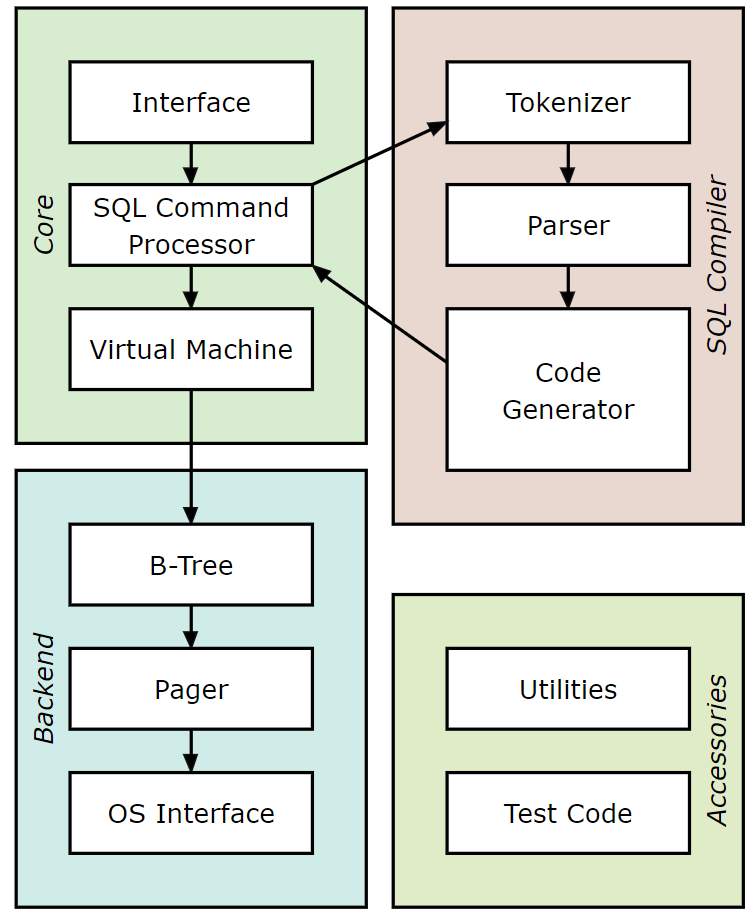
https://www.sqlite.org/arch.html
Part 1 - Introduction and Setting up the REPL
https://cstack.github.io/db_tutorial/parts/part1.html
REPL指的是"Read-Eval-Print Loop",是一个交互式的编程环境,通常用于解释性语言
Part 2 - World’s Simplest SQL Compiler and Virtual Machine
https://cstack.github.io/db_tutorial/parts/part2.html
The “front-end” of sqlite is a SQL compiler that parses a string and outputs an internal representation called bytecode.
Part 3 - An In-Memory, Append-Only, Single-Table Database
将行放入内存,需要紧凑化处理。
Part 4 - Our First Tests (and Bugs)
strtok() vs scanf()
后者不会检查字段长度。
Part 5 - Persistence to Disk
缓存命中,
1 | vim mydb.db |
Part 7 - Introduction to the B-Tree
A B-Tree is different from a binary tree (the “B” probably stands for the inventor’s name, but could also stand for “balanced”). Here’s an example B-Tree:
SQLlite 使用的是B+
| B-tree | B+ tree | |
|---|---|---|
| Pronounced | “Bee Tree” | “Bee Plus Tree” |
| Used to store | Indexes | Tables |
| Internal nodes store keys | Yes | Yes |
| Internal nodes store values | Yes | No |
| Number of children per node | Less | More |
| Internal nodes vs. leaf nodes | Same structure | Different structure |
例子:
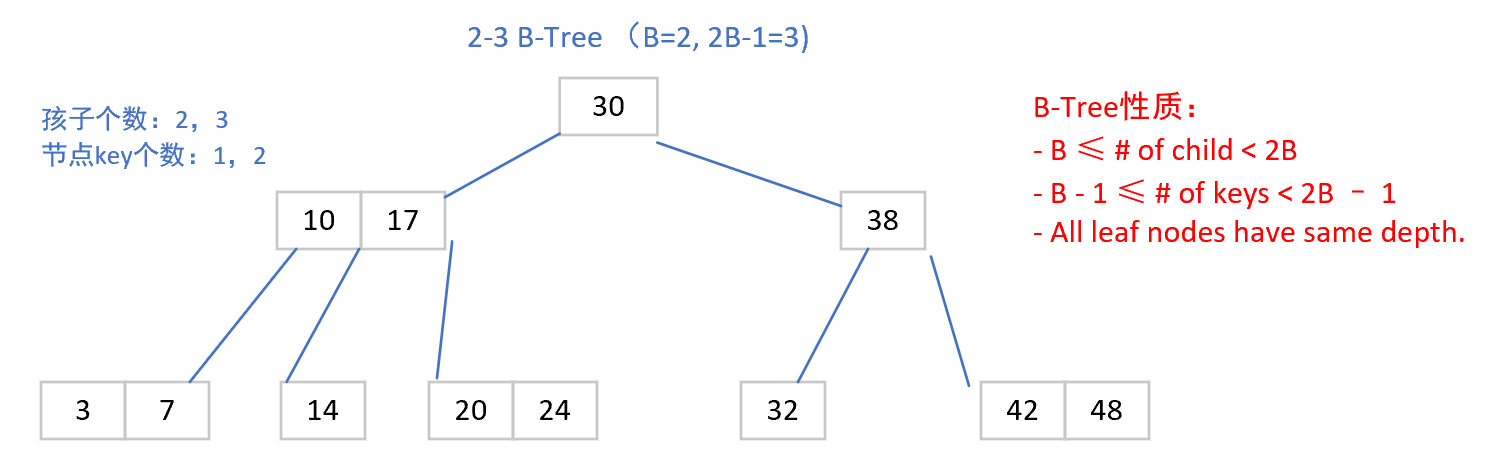
为什么选择树结构?
| Unsorted Array of rows | Sorted Array of rows | Tree of nodes | |
|---|---|---|---|
| Pages contain | only data | only data | metadata, primary keys, and data |
| Rows per page | more | more | fewer |
| Insertion | O(1) | O(n) | O(log(n)) |
| Deletion | O(n) | O(n) | O(log(n)) |
| Lookup by id | O(n) | O(log(n)) | O(log(n)) |
- changing the format of our table from an unsorted array of rows to a B-Tree.
- single-node tree
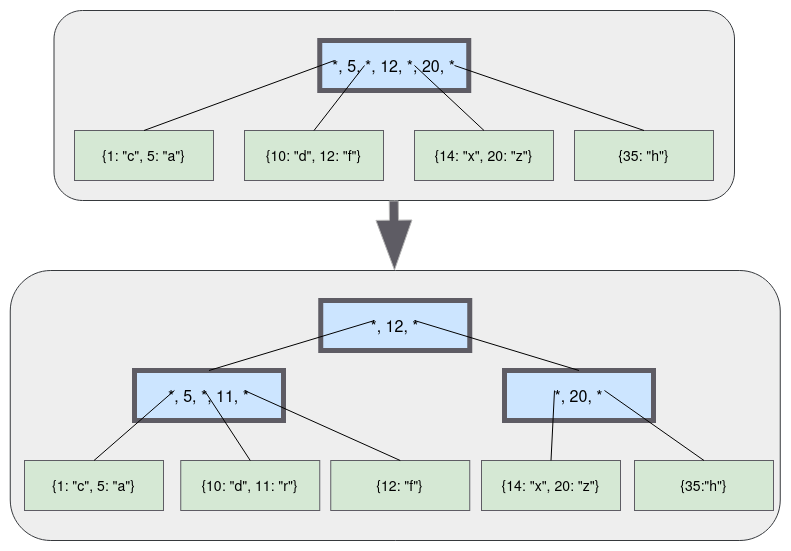
B+树
1. 计算
假设一个page 1KB
叶子节点内的cell数:默认定义为阶数-1, 但实际上可以很大,填充page即可。
- 32阶B+树,高度为3,默认容纳这么多记录。节点数*每个节点内数量。
-
32阶B+树,高度为4,默认容纳这么多记录。叶子节点数*每个节点内数量。
每层节点数分别为:1,32,3232,32 * 3232,共计 33,825个节点,约33MB
SQLlite 阶数常为32或者64
2.1 B+树的定义

各种资料上B+树的定义各有不同,一种定义方式是关键字个数和孩子结点个数相同。这里我们采取维基百科上所定义的方式,即关键字个数比孩子结点个数小1,这种方式是和B树基本等价的。上图就是一颗阶数为4的B+树。
除此之外B+树还有以下的要求。
1)B+树包含2种类型的结点:内部结点(也称索引结点)和叶子结点。根结点本身即可以是内部结点,也可以是叶子结点。根结点的关键字个数最少可以只有1个。
2)B+树与B树最大的不同是内部结点不保存数据,只用于索引,所有数据(或者说记录)都保存在叶子结点中。
3) m阶B+树表示了内部结点最多有m-1个关键字(或者说内部结点最多有m个子树),阶数m同时限制了叶子结点最多存储m-1个记录。
4)内部结点中的key都按照从小到大的顺序排列,对于内部结点中的一个key,左树中的所有key都小于它,右子树中的key都大于等于它。叶子结点中的记录也按照key的大小排列。
5)每个叶子结点都存有相邻叶子结点的指针,叶子结点本身依关键字的大小自小而大顺序链接。
2.2 B+树的插入操作
1)若为空树,创建一个叶子结点,然后将记录插入其中,此时这个叶子结点也是根结点,插入操作结束。
2)针对叶子类型结点:根据key值找到叶子结点,向这个叶子结点插入记录。插入后,若当前结点key的个数小于等于m-1,则插入结束。否则将这个叶子结点分裂成左右两个叶子结点,左叶子结点包含前m/2个记录,右结点包含剩下的记录,将第m/2+1个记录的key进位到父结点中(父结点一定是索引类型结点),进位到父结点的key左孩子指针向左结点,右孩子指针向右结点。将当前结点的指针指向父结点,然后执行第3步。
3)针对索引类型结点:若当前结点key的个数小于等于m-1,则插入结束。否则,将这个索引类型结点分裂成两个索引结点,左索引结点包含前(m-1)/2个key,右结点包含m-(m-1)/2个key,将第m/2个key进位到父结点中,进位到父结点的key左孩子指向左结点, 进位到父结点的key右孩子指向右结点。将当前结点的指针指向父结点,然后重复第3步。
下面是一颗5阶B树的插入过程,5阶B数的结点最少2个key,最多4个key。
a)空树中插入5

b)依次插入8,10,15

c)插入16

插入16后超过了关键字的个数限制,所以要进行分裂。在叶子结点分裂时,分裂出来的左结点2个记录,右边3个记录,中间key成为索引结点中的key,分裂后当前结点指向了父结点(根结点)。结果如下图所示。

当然我们还有另一种分裂方式,给左结点3个记录,右结点2个记录,此时索引结点中的key就变为15。
d)插入17

e)插入18,插入后如下图所示

当前结点的关键字个数大于5,进行分裂。分裂成两个结点,左结点2个记录,右结点3个记录,关键字16进位到父结点(索引类型)中,将当前结点的指针指向父结点。

当前结点的关键字个数满足条件,插入结束。
f)插入若干数据后

g)在上图中插入7,结果如下图所示

当前结点的关键字个数超过4,需要分裂。左结点2个记录,右结点3个记录。分裂后关键字7进入到父结点中,将当前结点的指针指向父结点,结果如下图所示。

当前结点的关键字个数超过4,需要继续分裂。左结点2个关键字,右结点2个关键字,关键字16进入到父结点中,将当前结点指向父结点,结果如下图所示。

当前结点的关键字个数满足条件,插入结束。
2.3 B+树的删除操作
如果叶子结点中没有相应的key,则删除失败。否则执行下面的步骤
1)删除叶子结点中对应的key。删除后若结点的key的个数大于等于Math.ceil(m-1)/2 – 1,删除操作结束,否则执行第2步。
2)若兄弟结点key有富余(大于Math.ceil(m-1)/2 – 1),向兄弟结点借一个记录,同时用借到的key替换父结(指当前结点和兄弟结点共同的父结点)点中的key,删除结束。否则执行第3步。
3)若兄弟结点中没有富余的key,则当前结点和兄弟结点合并成一个新的叶子结点,并删除父结点中的key(父结点中的这个key两边的孩子指针就变成了一个指针,正好指向这个新的叶子结点),将当前结点指向父结点(必为索引结点),执行第4步(第4步以后的操作和B树就完全一样了,主要是为了更新索引结点)。
4)若索引结点的key的个数大于等于Math.ceil(m-1)/2 – 1,则删除操作结束。否则执行第5步
5)若兄弟结点有富余,父结点key下移,兄弟结点key上移,删除结束。否则执行第6步
6)当前结点和兄弟结点及父结点下移key合并成一个新的结点。将当前结点指向父结点,重复第4步。
注意,通过B+树的删除操作后,索引结点中存在的key,不一定在叶子结点中存在对应的记录。
下面是一颗5阶B树的删除过程,5阶B数的结点最少2个key,最多4个key。
a)初始状态

b)删除22,删除后结果如下图

删除后叶子结点中key的个数大于等于2,删除结束
c)删除15,删除后的结果如下图所示

删除后当前结点只有一个key,不满足条件,而兄弟结点有三个key,可以从兄弟结点借一个关键字为9的记录,同时更新将父结点中的关键字由10也变为9,删除结束。

d)删除7,删除后的结果如下图所示

当前结点关键字个数小于2,(左)兄弟结点中的也没有富余的关键字(当前结点还有个右兄弟,不过选择任意一个进行分析就可以了,这里我们选择了左边的),所以当前结点和兄弟结点合并,并删除父结点中的key,当前结点指向父结点。

此时当前结点的关键字个数小于2,兄弟结点的关键字也没有富余,所以父结点中的关键字下移,和两个孩子结点合并,结果如下图所示。

框架项目
libevent
file:///C:/Users/63517/Documents/libevent%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90.pdf
2.0.21 https://src.fedoraproject.org/repo/pkgs/libevent/libevent-2.0.21-stable.tar.gz/b2405cc9ebf264aa47ff615d9de527a2/
错误
1. Segmentation Fault(段错误)定位
valgrind
1 | gcc -g -o your_program your_program.c |
1 | valgrind --tool=memcheck --leak-check=full ./db |
- Address 0x4a3af30 is 0 bytes after a block of size 512 alloc’d
访问越界,比如分配了512,
makefile
- 如果一行太长,用/连接
1 | SRC_SERVER = array.c connect_manager.c connection_table.c connection.c \ |
TCP server
- [ ] return msg