
STL数据结构
结构体指针:
指针为NULL:不指向任何有效内存
哈希表:
- 数组方式:链表解决冲突。时间复杂度为O(1),实在理想情况下的, 没有冲突情况下的情况。 如果冲突较多,很可能达到O(n)
std::map使用红黑树实现的,查找删除插入操作平均复杂度为O(logN)- 在实际的生产环境中,通常会使用更为复杂的哈希表实现,例如采用开放寻址法、使用动态数组,以及考虑哈希表的负载因子等因素。
STL
不是所有 STL 容器都返回引用。不同的容器函数在返回值上有不同的行为。以下是一些常见的 STL 容器函数返回类型的情况:
-
返回引用的情况:
- 对于
std::vector、std::deque和std::list的back()、front()函数,它们返回的是引用。 std::map和std::unordered_map的operator[]返回键对应的值的引用。
- 对于
-
返回值的情况:
- 对于
std::vector、std::deque和std::list的pop_back()、pop_front()函数,它们删除元素并返回被删除元素的拷贝。 std::map和std::unordered_map的operator[]在键不存在时会插入默认值,并返回这个默认值的引用。
- 对于
-
返回迭代器的情况:
- 对于
std::set和std::unordered_set的insert()、erase()函数,它们返回的是迭代器,指向插入或删除的元素位置。
在使用容器函数时,建议查看相关文档以了解返回类型的具体情况。不同的容器和不同的函数可能有不同的行为。
- 对于
下面返回元素的方法都是返回的引用, 存在引用到值的隐式转换, 转为副本,
1 | int& ele = list.back(); // 修改list内元素 |
vector向量是一种动态数组(可变长数组),在运行时能根据需要自动改变数组大小。
1 |
|
STL的list是数据结构中的双向链表,内存空间不连续,通过指针来访问
特点:可高效率在任意地方删除与插入,但不支持随机访问(访问较慢)
不支持list.find(), 只能遍历查找
1 |
|
1 |
|
1 |
|
1 |
|
1 | map<string, int> mp; // 定义一个将string映射成int的map |
pair
迭代器:
迭代器是一个类,容器返回的是迭代器对象。
但是迭代器类对很多操作符做了重载。
- 解引用操作 (
*): it 指向的是 值。
1 | std::vector<int> myVector = {1, 2, 3, 4, 5}; |
- 箭头操作符 (
->): it 指向的是对象时候。
1 | // map元素就是pair对象 |
- 递增操作 (
++): 将迭代器移动到容器的下一个位置。
1 | std::list<int> myList = {1, 2, 3, 4, 5}; |
- 比较操作 (
==,!=,<,<=,>,>=): 比较两个迭代器的相对位置。 是否指向的是同一个元素
1 | std::vector<int> myVector = {1, 2, 3, 4, 5}; |
cs106B
课程简介
- 2018-winter-课程主页,2022winter,
- 视频链接
- 编辑环境:QTcreater, The Stanford C++ Library (2023.1版本)
- 课程时间:30小时
- 教科书:[[ProgAbs.pdf]]
- 资源:2021-winter
2018spring作业,2024-winter-作业,各年CS106B的地址 - schedule:
| 日期 | 1 | |||
|---|---|---|---|---|
环境:
使用blankProject配置
// TODO
Stanford CPP Lib:
Qt Creator中的.pro
在QT中,有一个工具qmake可以生成一个makefile文件,它是由.pro文件生成而来的.
TEMPLATE
app: 用于构建应用程序。这是一个典型的 GUI 或控制台应用程序项目。lib: 用于构建库。subdirs: 用于构建包含子项目的项目。这个模板允许你组织多个项目并在一个.pro文件中构建它们。
CONFIG
| 选项 | 说明 |
|---|---|
| debug,release | 指定构建模式 |
| console | 只用于app模板,指定项目是控制台程序 |
| qt | 表示项目使用QT库 |
| thread | 启用线程支持。当CONFIG包括qt时启用,这是缺省设置。 |
| c++11 | 启用c++11支持。 |
| windows | 只用于app模板 应用程序是一个windows的窗口应用程序 |
| staticlib | 只用于“lib”模板,库一个静态库 |
| dll | 只用于”lib”模板,库是一个共享库(dll) |
| plugin | 只用于“lib”模板,库是一个插件,这会使dll选项生效 |
| silent | 启用“安静”构建。 |
| depend_includepath | |
| QT |
functions
- 函数声明
- 参数默认值
1 | void printline(int width=10,char letter='*') |
- 参数传递
value semantics: int,double类型传递,值复制传入函数,不影响实参。
reference semantics: &修饰,参数将链接到实参地址。
1 | void quadratic(int a,int b,int c, double &root1,double& root2) |
- output parameters:
void quadratic(int a,int b,int c, double &root1,double& root2); - Procedural decomp:
main函数包含概括流程,其他函
strings
1 | # |
- characters
1 | // |
!()[https://raw.githubusercontent.com/ddongzi/ddongzi.github.io/main/image/markdown/20240111173320.png]
operators
1 | //concat |
![[Pasted image 20240111173850.png]]
string::npos
3. exercise:
1 | // a作为复制传入,不影响实参,b作为引用传入,会影响 |
- string user input:
- cin 读取字符串输入, 一次读取一个词
1 | cout<<"name:"; |
- c++ 标准库,getline读取一行
1 | string name; |
- stanford 库getLine 读取一行
1 |
|
- 可行的操作
1 | //字符串相加 |
- 不可行的操作
1 | string s="hi"+"joe"; //c string + c string |
- 空字符串
- " \0000" 是由四个空字符组成的字符串,它占据了四个字节的内存空间。看作一个包含三个空字符和一个字符串结束符的字符串。
- “” 是一个空字符串,表示字符串中没有任何字符,它只包含一个字符串结束符(‘\0’),占据一个字节的内存空间。
所以,虽然两者在逻辑上都代表空字符串,但是它们在内存中占据的空间不同。
在使用上,因为字符串库会处理字符串的细节,使得对空字符串的操作在逻辑上是等效的。
判断空字符串:- s.empty()
- s=“”
- s.length()== 0
空字符表示为:'\x0''\0'
字符串:"\x00"表示一个含空字符的字符串(c语言),并不是空字符串。他的长度为1。 通过string构造即可转换空字符串。
1 | // "\0000"后面的都无效,因为读到结尾了 |
IO stream
- 文件读写
- ifstream, ofsteam 类
- 分别继承于isteam, ostream
- cin is an ifsteam, cout is an ofsteam
- ifsteam members
1 | # |
- line-based IO 例子:
1 | ifsteam input; |
不正确的:
1 | while(!input.fail()){ |
-
操作符,每次读取一个单词
- 读取单词,不成功将stream置为失败,返回false
1 | input>>word; |
1 | //读取所有单词 |
- 类型不匹配,手动转换
1 | string word; |
- filelib.h
Collections
- STL vs stanford c++ lib(SPL)
- Vectors(Lists)
- 动态数组
1 | Vector<int> nums {1,2,3}; |
- 为什么不用数组
int nums[5] {1,2,3} - vector members:
1 | v.insert(2,34); |
- Grid :
- 矩阵结构,比二维数组更强
1 | Grid<int> matrix(3,4); |
- 作为参数传递
是完全复制(值传递)进行传递的,非常慢。所以通过&引用传递。
如果不修改该grid,声明为const。
1 | int compuerSum(const Grid<int>& matrix); |
- 练习Grid。
![[Pasted image 20240113215959.png]]
Lecture5
- 嵌套列表
1 | Vector<Vector<int>> vv; |
- 链表
1 | # |
- ADTS: 抽象数据类型
- ADT: 抽象数据类型。特殊数据集合,有一些上面的特定操作
- 描述一个集合做什么, 而不是如何做(细节)
- 如Vector和LinkedList都实现一个ADT:list
- 其他的有stack, queue。。
- stack
- 不能使用
stack[i]索引访问
1 | while(!s.isEmpty()){ |
- 队列
- 不要在遍历时候去 出入队列
1 | //好的做法 |
- 练习:计算文件中单词次数。
1 | void wordCount(const string & filename) |
- set
- 可以高效执行add, remove, search
- 没有下表index
- 两种实现
- set:二叉树的链式结构
- 有序,
- 需要有比较函数
- hashset: 哈希表 数组
- 无序
- 需要hash函数
![[Pasted image 20240115152733.png]]
- set:二叉树的链式结构
map
- 两种实现
- map:二叉树的链式结构
- 有序,
- 需要有比较函数
- hashmap: 哈希表 数组
- 无序
- 需要hash函数
- map:二叉树的链式结构
1 | Map |
Recurise
过程: 可以理解为树深度优先遍历。决策树
fractal
1 | snowflake(window,x,y,size,level); |
stanford graphics lib
![[Pasted image 20240117204102.png]]
cantor set:
1 | void cantorSet(GWindow &window,int x,int y,int length, int level) |
1 | void cantorSet(GWindow &window,int x,int y,int length, int level) |
evaluate :
1 | /** |
1 | void printAllBinaryHelper(int digits,string output) |
Exhaustive research and backtracking
穷举搜索常用递归实现。
exercise : printAllBinary(n)用递归实现
backtracking:
- 一种暴力搜索方法,即所有路径。
- 找到符合条件的路径。
伪代码:
1 | function Explore(decisions): |
- Key tasks
-Figure out appropriate smallest unit of work(decision).
-Figure out how to enumerate all possible choices /options for it.
1 | int calls=0; |
![[Pasted image 20240123110501.png]]
优化: 去除不必要的递归
1 | int calls=0; |
Escape Maze Exercise:
![[Pasted image 20240123114433.png]]
Maze class:
1 | # |
Lecure 10: backtracking3
“Arm’s” length recursion:
- “Arm’s” length recursion : A poor(糟糕的) style where unnecessary tests are performed before performing recursive calls.
-Typically, the tests try to avoid making a call into what would otherwise(本来是) be a base case. - Example : escapeMaze
-Our code recursively tries to explore up,down,left,right.
-Some of those directions may lead to walls or off the board. Shouldn’t we test before making calls in these directions?
Escape Maze solution
1 | // This code is better. |
“Arm’s” length escapeMaze
1 | // This code is bad. It uses arm's length recursion. |
Exercise: sublists
- write a function
subliststhat finds every possible sub-list of given vector. A sub-list of a vector V contains >=0 of V’s elements.
1 | // v: avaliable, chosen: 目前已选择 |
The “8 Queens” problem
wiki
![[Pasted image 20240125120553.png]]
- Consider the problem of trying to place 8 queens on a chess board such that no queen can attack another queen.
-What are the choices?
-How do we “make” or “un-make” a choice?
-How do we know when to stop?
1 | void solveQueenHelper(Board& board , int col){ |
Lecture 12
Classes;Arrays;Implementing a Collection
Elements of a class:
- member var. ;
- member func.
- constructor:
Interface vs code:
- C++ separates classes into two kinds of code files:
-.h : A “header” file containing the interface(declarations)
-.cpp : A “source” file containing definitions (method bodies)- class Foo => must write both Foo.h and Foo.cpp
- The content of .h files is
##includeinside .cpp files
Class declaration(.h)
1 | // |
Class example(v1)
1 | # |
using objects.
1 | BnakAccount ba1("may",1.0); |
The implicit parameter
Member func. bodies
- In ClassName.cpp, we write bodies for the member functions that were declared in the .h file.
1 | //ClassName.cpp |
Constructors
- no return type is specified.
- without constructor:
1
2
3BankAccount ba;
ba.name="aa";
ba.balance=1.2; - with constructor: (better)
1 | BankAccount ba ("A",1.2); |
Arrays(11.3)
type *name = new type[length];
- A dynamically allocated array.
- name is a pointer
- The memory allocated for the array must be manually released or else the program will have a memory leak
type name[length];we will not use this syntax.
-A fixed array
-Stored in a different place in memory. The first syntax is heap. The second is stack.
Initialized?
type *name = new type[length]; // uninitilized
type *name = new type[length](); // initilized to 0
两种对象创建方式:
- 栈上创建:
Type obj - 堆上动态分配:new , delete
Exercise:
- Let’s implement a stack using an unfilled array.
-We’ll call it ArrayStack. It will be very similar to the C++ stack.
-its behavior:- push(value)
- pop()
- peek()
- isEmpty()
- toString()
-size: - default array of 10.
1 | # |
Lecture 13:
Pointers and Linked Lists
Linked data structures
- Some collections store data using linked sequences of nodes.
-examples : Set, Map, LinkedList
Structs
- struct : a lightweight class; a template for related data.
-Members are public by default;
1 | struct Date{ |
Null/garbage pointers
- null pointer : Memory address 0
- uninitialized pointer : points to a random address.
1 | int *p1=nullptr; |
Pointer to struct
Type *p=new Type(param);
1 | // 1) non-pointer |
A list node structure
1 | struct ListNode{ |
Traversing a list
1 | ListNode *cur=front; |
Lecure 14
Linked list
Lecure 15
Array/Linked List Class; PQs and Binary Heaps
The keyword const:
- a const reference paramter can’t be modified by the func.
void foo(const BankAccount& ba){} - a const member func. can’t change the object’s state.
1
2
3
4// .h and .cpp
class BankAccount{
double getBalance() const;
}
1 | void foo(const ArrayStack& stack){ |
Operator overloading(6.2)
- Redefining the behavior of a common operator .
- Syntax: -for example, a+b becomes operator +(Foo& a, Foo &b)
1
2
3
4returnType operator op(paramters); //.h
returnType operator op(paramters){//.cpp
statements;
}
-for example, list1+list2
-cout<<stack<<endl;实际上就是重载了<<。
Make objects printable
- To make it easy to print your object to cout, overload <<
1 | // 返回引用 |
-ostream is a base class, include io ...
1 | //.h |
Destuctor(12.3)
1 | //.h |
- destructor : Called when the objects is deleted by the program.
-Useful if your object needs to free any memory as it dies.- delete any pointers stored as private members.
- delete [] any arrays stored as private members.
-when leave {} scope, called.
-在析构函数中,手动删除new 的内存,其他会被程序自动回收,
1 | ArrayStack::~ArrayStack(){ |
A LinkedIntList class
- Similar public members to Vector.
- Implemented as a chain of linked nodes.
-keeps a private pointer to its front node
-nullptr is the end of the list;
friend: 运算符重载写在成员函数,使得其可以访问成员变量(私有属性)。
friend ostream& operator <<(ostream& out, LinkedIntList& list);
返回指针和返回指针引用:
1 | //返回指针,即返回get 函数里result指针的 完全副本。 |
1 | # |
Priority Queues and Heaps
-
Provides fast access to its highest-priority element.
-enqueue : add an element at a given priority
-peek : returns highest-priority value
-dequeue ; remove/return highest-priority value
![[Pasted image 20240126130238.png]]
![[Pasted image 20240126130321.png]]
PQ as array/vector
![[Pasted image 20240126130432.png]]
Heaps
![[Pasted image 20240126130543.png]]
HW1-完美数:2024
Perfect numbers
A perfect number is an integer that is equal to the sum of its proper divisors.
The first perfect number is 6 because its proper divisors are 1, 2, and 3, and 1 + 2 + 3 = 6. The next perfect number is 28, which equals the sum of its proper divisors: 1 + 2 + 4 + 7 + 14.
An exhaustive algorithm
暴力搜索:遍历每个数,对每个数,找到所有的因子,检查和。
Observing the runtime
When you are prompted in the console to “Select the test groups you wish to run,” enter 0 for “None” and the program will instead proceed with the ordinary main function.
Q1. Roughly how long did it take your computer to do the search? How many perfect numbers were found and what were they?
It would be more convenient to run several time trials in sequence and have the program itself measure the elapsed time. The SimpleTest framework can help with this task, so let’s take a detour there now.
What is SimpleTest?
SimpleTest:
TIME_OPERATION: 最好10-60s
For now, focus on use of STUDENT_TEST, EXPECT, EXPECT_EQUAL, and TIME_OPERATION, as these are the features you will use in Assignment 1.
Practice with TIME_OPERATION
Q2. Make a table of the timing results for
findPerfectsthat you observed. (old-school table of text rows and columns is just fine)
To visualize the trend, it may help to sketch a plot of the values (either by hand or using a tool like https://www.desmos.com/calculator).
Q3. Does it take the same amount of work to compute
isPerfecton the number 10 as it does on the number 1000? Why or why not? Does it take the same amount of work forfindPerfectsto search the range of numbers from 1-1000 as it does to search the numbers from 1000-2000? Why or why not?
the first four perfect numbers pop out in a jif (6, 28, 496, 8128) because they are encountered early in the search, but that fifth one is quite a ways off – in the neighborhood of 33 million.
Q4. Extrapolate from the data you gathered and make a prediction: how long will it take
findPerfectsto reach the fifth perfect number?
Digging deeper into testing
Here are some further explorations to do with SimpleTest:
- Introduce a bug into
divisorSumby erroneously initializingtotalto 1 instead of zero. Rebuild and run the tests again. - Add a new
STUDENT_TESTcase that callsisPerfecton a few different negative inputs.
Q5. Do any of the tests still pass even with this broken function? Why or why not?
Streamlining and more testing
However, there is a neat little optimization that can significantly streamline the process.The function divisorSum runs a loop from 1 to N to find divisors, but this is a tad wasteful, as we actually only need to examine divisors up to the square root of N.In other words, we can take advantage of the fact that each divisor that is less than the square root is paired up with a divisor that is greater than the square root.
You are to implement a new function smarterSum:long smarterSum(long n)that produces the same result as the original divisorSum but uses this optimization to tighten up the loop.
After adding new code to your program, your next step is to thoroughly test that code and confirm it is bug-free.Because you already have the vetted function divisorSum at your disposal, a clever testing strategy uses EXPECT_EQUAL to confirm that the result from divisorSum(n) is equal to the result from smarterSum(n).
Q6. Explain your testing strategy for
smarterSumand how you chose your specific test cases that lead you to be confident the function is working correctly.
Now with confidence in smarterSum, implement the following two functions that build on it:
bool isPerfectSmarter(long n)
void findPerfectsSmarter(long stop)
The code for these two functions is very similar to the provided isPerfect and findPerfects functions, basically just substituting smarterSum for divisorSum. Again, you may copy-paste the existing implementations, and make small tweaks as necessary.
Now let’s run time trials to see just how much improvement we’ve gained.
Q7. Record your timing results for
findPerfectsSmarterinto a table.
Our previous algorithm grew at the rate N^2, while this new version is N√N, since we only have to inspect √N divisors for every number along the way.
Q8. Make a prediction: how long will
findPerfectsSmartertake to reach the fifth perfect number?
Mersenne primes and Euclid
A Mersenne number is a number that is one less than a power of two, i.e., of the form 2k-1 for some integer k. A Mersenne number that is prime is called a Mersenne prime. The Mersenne number 25-1 is 31 and 31 is prime, making it a Mersenne prime.
Mersenne primes are quite elusive; the most recent one found is only the 51st known and has almost 25 million digits! Verifying that the found number was indeed prime required almost two weeks of non-stop computing.
Back in 400 BCE, Euclid discovered an intriguing one-to-one relationship between perfect numbers and the Mersenne primes. Specifically, if the Mersenne number 2k-1 is prime, then 2(k-1) * (2k-1) is a perfect number. The number 31 is a Mersenne prime where k = 5, so Euclid’s relation applies and leads us to the number 24 * (25-1) = 496 which is a perfect number. Neat!
Turbo-charging with Euclid
The final task of the warmup is to leverage the cleverness of Euclid to implement a blazingly-fast alternative algorithm to find perfect numbers that will beat the pants off of exhaustive search. Buckle up!
Your job is to implement the function:
long findNthPerfectEuclid(long n)
The exhaustive search algorithm painstakingly examines every number from 1 upwards, testing each to identify those that are perfect. Taking Euclid’s approach, we instead hop through the numbers by powers of two, checking each Mersenne number to see if it is prime, and if so, calculate its corresponding perfect number. The general strategy is outlined below:
- Start by setting
k = 1. - Calculate (Note: C++ has no exponentiation operator, instead use library function
pow) - Determine whether
mis prime or composite. (Hint: a prime number has adivisorSumandsmarterSumequal to one. Code reuse is your friend!) - If
mis prime, then the value is a perfect number. If this is thenthperfect number you have found, stop here. - Increment
kand repeat from step 2.
The call findNthPerfectEuclid(n) should return the nth perfect number. What will be your testing strategy to verify that this function returns the correct result? You may find this table of perfect numbers to be helpful. One possibility is a test case that confirms each number is perfect according to your earlier function, e.g. EXPECT(isPerfect(findNthPerfectEuclid(n))).
1 | STUDENT_TEST("findNthPerfectEuclid(n)"){ |
Q9. Explain how you chose your specific test cases and why they lead you to be confident
findNthPerfectEuclidis working correctly.
But if you try for the sixth, seventh, eighth, and beyond, you can run into a different problem of scale. The super-fast algorithm works in blink of an eye, but the numbers begin to have so many digits that they quickly exceed the capability of the long data type.
Warmup conclusions
You should have answers to questions Q1 to Q9 in short_answer.txt.
Your code should also have thoughtful comments, including an overview header comment at the top of the file.
HW1- Soundex Search : 2024
Soundex算法是一种用于对英语姓氏进行发音编码的算法。它旨在将类似发音的姓氏映射到相同的编码,从而允许在搜索引擎或数据库中快速查找发音相似的姓氏。
Why phonetic name matching is useful
Traditional string matching algorithms that use exact match or partial/overlap match perform poorly in this messy milieu of real world data. In contrast, the Soundex system groups names by phonetic structure to enable matching by pronunciation rather than literal character match. This makes tasks like tracking genealogy or searching for a spoken surname easier.
The Soundex algorithm is a coded index based on the way a name sounds rather than the way it is spelled. Surnames that sound the same but are spelled differently, like “Vaska,” “Vasque,” and “Vussky,” have the same code and are classified together.
How Soundex codes are generated
The Soundex algorithm operates on an input surname and converts the name into its Soundex code. A Soundex code is a four-character string in the form of an initial letter followed by three digits, such as Z452. The initial letter is the first letter of the surname, and the three digits are drawn from the sounds within the surname using the following algorithm:
- Extract only the letters from the surname, discarding all non-letters (no dashes, spaces, apostrophes, …).
- Encode each letter as a digit using the table below.
| Digit | represents the letters |
|---|---|
| 0 | A E I O U H W Y |
| 1 | B F P V |
| 2 | C G J K Q S X Z |
| 3 | D T |
| 4 | L |
| 5 | M N |
| 6 | R |
- Coalesce adjacent duplicate digits from the code (e.g.
222025becomes2025). - Replace the first digit of the code with the first letter of the original name, converting to uppercase.
- Discard any zeros from the code.
- Make the code exactly length 4 by padding with zeros or truncating the excess.
Q10. What is the Soundex code for “Angelou”? What is the code for your own surname?
such as, Angelou(A524),Curie (C600) and “O’Conner” (O256).
Decomposing the problem
Q11. Before writing any code, brainstorm your plan of attack and sketch how you might decompose the work into smaller tasks. Briefly describe your decomposition strategy.
Testing, testing, testing
Brainstorm what those missing cases are and then add them. Think about edge cases that could lurk in the extremes or cases that are uniquely distinguished from the provided tests, such as a completely empty string or a string composed of only non-letter characters.
Your goal in writing tests is to enumerate a comprehensive set of tests that brings any bugs in the code to light so you can debug and fix them. Good tests are the key to writing robust software. A great developer is not only a great coder, but also a great tester.
Debugging a failing test case
Now run the tests while using the debugger. When you hit the breakpoint, single step through the call to lettersOnly while watching the debugger’s variables pane to see how the values are changing. This “step-and-watch” approach is the same as you used in the Assignment 0 debugging tutorial.
Using the debugger should help you find the bug —once you understand it, go ahead and fix it!
1 | STUDENT_TEST("Test exclude of punctuation, digits, and spaces"){ |
Implementing the Soundex algorithm
Now for each subsequent step of the algorithm (encode, coalesce duplicates, and so on), follow the same process:
- Identify the next small task of the algorithm to implement.
- Define a new helper function to accomplish that task.
- Write student tests that confirm the expected behavior of the new function.
- Fill in the code for your helper function, debugging as you go. Continue writing code and debugging until you have passed all the tests from the previous step.
- Rinse and repeat.
Your eventual goal is to implement the function:
string soundex(string s)
, but you should also add tests of your own to ensure you have covered the full possible range of inputs.
Developing a census search program
This console program allows a user to perform a Soundex search on a database of surnames. Implement the following function prototype:
void soundexSearch(string filepath)
The one argument to soundexSearch is the name of a text file containing a database of names.he program then repeatedly allows the user to enter a surname to look up in the database. For each surname that is entered, the program calculates the Soundex code of the entered name and then finds all names in the database that have a matching Soundex code.
Here are the steps for the program:
- Read a database of surnames from the specified text file.
- This step is provided for you in the starter code. The “database” is simply a
Vector<string>.
- This step is provided for you in the starter code. The “database” is simply a
- Prompt the user to enter a surname.
- The function
getLinefrom"simpio.h"will be helpful here.
- The function
- Compute the Soundex code of the surname.
- Iterate over the Vector of names, compute Soundex code of each name, and gather a result Vector containing those surnames with a matching code.
- Print the matches in sorted order.
- The Vector has a handy
sort()operation (you can usevec.sort()wherevecis the name of your vector), and you can print a vector using the<<operator, e.g.cout << vec << endl;. Please note that thesort()function sorts the vector in place and does not return a value.
- The Vector has a handy
- Repeat steps 2-5 until the user indicates that they are done.
1 | Read file res/surnames.txt, 29409 names found. |
Assignment2:Problem One: Rising Tides
题目指导
Your task in this part of the assignment is to build a tool that models flooding due to sea level rise. (模拟海平面上升带来的洪水)
Your task is to implement a function,
Grid *floodedRegionsIn*(const Grid& terrain, const Vector& sources, double height);
- returns a Grid indicating, for each spot in the terrain, whether it’s under water (true) or above the water (false).
Breadth-first search is typically implemented by using a queue that will process every flooded location.
1 | create an empty queue; |
Once you’re passing all the tests, click the “Rising Tides” option to see your code in action!
Some notes on this problem:
- Curious about an edge case.?
![[Pasted image 20240124141020.png]]
Assignment2:Part Two: You Got Hufflepuff!
Many personality quizzes – including the one you’ll be building – are based on a what’s called the fivefactor model.:openness, conscientiousness, extraversion, agreeableness, and neuroticism.
As you take the personality quiz and answer questions, the computer updates your scores in these five categories based on how you answer each question. Your score in each category begins at zero and is then adjusted in response to your answers. At the end of the quiz, the program reports the fictional character whose scores are most similar to yours.
![[Pasted image 20240124141708.png]]
The Assignment at a Glance
Your task is to implement the data processing framework that works behind the scenes to tabulate scores from the personality quiz and determines who the user is most similar to. We’ll use your code to select which questions to ask the user, to determine the user’s score from their quiz answers, to determine the similarity between the user and a fictional character, and to select the fictional character who is most similar to the user.
Milestone One: Select Random Questions
Question randomQuestionFrom(Set& unaskedQuestions);
Your should implement the function to do the following:
- choose a random question from the Set,
- remove it from the Set,
- then return it.
The idea is that someone could call this function multiple times to pick personality quiz questions to ask the user.
We recommend that you use the randomElement() function, which is provided in "set.h".
If the input set provided to randomQuestionFrom is empty, then you should use the error() function you saw in Assignment 1 to report an error.
Test.
Milestone Two: Compute Scores From Question/Answer Pairs
1 | //-E +N I let others finish what they are saying |
Now, on to what you need to do for this milestone. We’ve written a piece of code that administers a personality quiz, recording the user’s answers in a variable of type Map. Here, the keys represent individual personality quiz questions, and the values represent the result the user typed in.As a refresher, a response of 1 means “strongly disagree,” while a response of 5 means “strongly agree.”
Your task is to write code that uses the data in that Map to determine the user’s OCEAN scores. Specifically, we’d like you to write a function :
Map scoresFrom(const Map& answers);
You should compute scores using the approach described earlier: for each question, weight the factors of that question based on the user’s answer (5 means “strongly agree” and adds doubles the weight of each factor; 4 means “agree” and adds the weight of each factor; 3 means “neutral” and adds zero to the weight of each factor, etc.).
As an example, suppose you were provided these questions and the indicated responses:
![[Pasted image 20240124144657.png]]
You should then ( result ) produce a Map where O maps to +5, E maps to -2, A maps to +1, and N maps to +4. To see where this comes from, let’s focus on the O component. The answer of 5 to “I am quick to understand things” adds 2 × (+1) = +2 to the O score, the answer of 4 to “I go my own way” adds 1 × (+1) = 1 to the O score, and the answer of 1 to “I become overwhelmed by events” adds (-2) × (-1) = +2 to the O score.
To summarize, here’s what you need to do:
Milestone Two
- Implement the scoresFrom function in YouGotHufflepuff.cpp.
- Use the provided tests to confirm that your code works correctly.
- Optionally, but not required: use STUDENT_TEST to add a test case or two of your own!
Some notes on this problem:
- In order to implement this function, you’ll need to iterate over the keys in the Map. To do so, use this syntax:
1 | for (KeyType var: map) { |
• Remember that the Map’s square bracket operator does automatic insertion if you look up a key that isn’t there. In the context of a Map, this means that if you look up a character that isn’t present in the map, it will automatically insert that key with the value 0.
• Although in the context of a personality quiz the keys in a Map will be some subset of O, C, E, A, and N, your function should work even if we have other keys in the factors maps. (For example, we might repurpose this code to work with a different set of factors than OCEAN.)
1 | Map<char, int> expected = { |
• Do not use the + or += operators to add two Maps. Adding them this way “form a new Map that uses all the key/value pairs from the two input maps, with duplicates resolved arbitrarily.” It does not mean “form a new Map by adding the two Maps’ elements pairwise.”
Milestone Three:
Once we have these scores, we need to find character is “closest” to the user’s scores. There are many ways to define “closest,” but one of the most common ways to do this uses something called the cosine similarity, which is described below.
![[Pasted image 20240124151254.png]]
Person 2 answered more questions, they had more opportunities to have numbers added or subtracted from each category
To correct for this, you’ll need to normalize the user’s scores. Borrowing a technique from linear algebra, assuming the user’s scores are o, c, e, a, and n, you should compute the value.
![[Pasted image 20240124151355.png]]
Your next task is to implement a function
Map<char,double> normalize(const Map<char,int>& scores); that takes as input a set of raw scores, then returns a normalized version of the scores.
There is an important edge case you need to handle. If the input Map does not contain any nonzero values, then the calculation we’ve instructed you to do above would divide by zero. (Do you see why?) To address this, if the map doesn’t contain at least one nonzero value, you should use the error() function to report an error.
Milestone Three
- Implement the normalize function in YouGotHufflepuff.cpp.
- Use the provided tests to confirm that your code works correctly.
- Optionally, but not required: use STUDENT_TEST to add a test case or two of your own!
Some notes on this problem:
- Remember that dividing two ints in C++ always results in an int. Check the textbook for details about how to divide two ints and get back a double.
- Instead, to compute square roots, include the header and use the
sqrtfunction.
Milestone Four: Implement Cosine Similarity
One measure we can use to determine how similar they are is to compute their cosine similarity
![[Pasted image 20240124152824.png]]Your next task is to write a function double cosineSimilarityOf(const Map& lhs, const Map& rhs); that takes as input two sets of normalized scores, then returns their cosine similarity using the formula given above.
Some notes:
- The two input maps are not guaranteed to have the same keys. For example, one map might have the keys A, C, and N, and the other might have the keys O and N. You should treat missing keys as if they’re associated with zero weight.
- You can assume that the two sets of input scores are normalized and don’t need to handle the case where this isn’t true.
- As above, while in the finished product this code will be used on OCEAN scores, this function should work equally well if the keys are arbitrary characters.
Milestone Five: Find the Best Match
1 | struct Person { string name; Map<char,int> scores; }; |
Person mostSimilarTo(const Map<char,int>& scores, const Set<Person>& people);
takes as input the user’s raw OCEAN scores and a Set of fictional people.
This function then returns the Person whose scores have the highest cosine similarity to the user’s scores.
As an edge case, if the people set is empty, you should call error() to report an error, since there’s no one to be similar to in that case.
Similarly, if the user’s scores can’t be normalized – or if any of the people in the input set have scores that can’t be normalized – you should call error() to report an error.
Some notes on this part of the problem:
- Remember that you can only compute cosine similarities of normalized scores.
- If there is a tie between two or more people being the most similar, you can break the tie in whatever way you’d like.
- As before, while we’re ultimately going to be using this code on OCEAN scores, your function should work regardless of what the keys in the different maps are.
Assignment 3. Recursion!
This assignment has four parts to it, and you have seven days to complete it. We recommend that you start this assignment early and make slow, steady progress throughout the week. Here’s a recommended timetable:
- Complete the Sierpinski Triangle within a day of this assignment going out.
- Complete Human Pyramids within two days of this assignment going out.
- Complete What Are YOU Doing? within four days of this assignment going out.
- Complete Shift Scheduling within seven days of this assignment going out.
Recursive problem-solving can take a bit of time to get used to, and that’s perfectly normal. Putting in an hour or two each day working on this assignment will give you plenty of time to adjust and gives you a comfortable buffer in case you get stuck somewhere.
Part One: The Sierpinski Triangle
As with many self-similar images, it’s defined recursively:
- An order-0 Sierpinski triangle is a regular, filled triangle.
- An order-n Sierpinski triangle, where n > 0, consists of three Sierpinski triangles of order n – 1, each half as large as the main triangle, arranged so that they meet corner-to-corner.
![[Pasted image 20240126143505.png]]
Every triangle drawn here is black; the white triangles represent places where no triangle was drawn.
Your task is to implement a function
1 | void drawSierpinskiTriangle(GWindow& window, |
that takes as input a window in which to draw the Sierpinski triangle, coordinates of the three points defining the corners of that triangle, and the order of that triangle, then draws the Sierpinski triangle of that order.If the order parameter is less than zero, use the error() function to report an error.
To draw a triangle, you can use this helpful drawTriangle function that we’ve provided:
1 | void drawTriangle(GWindow& window, |
This function takes in a GWindow in which to draw the triangle, along with the coordinates of its three corners, then draws a black triangle with the specified corner coordinates.
Part 1 Requirements
- Implement the
drawSierpinskiTrianglefunction inSierpinski.cpp. Don’t forget to handle the case where the order is negative.- Use the “Interactive Sierpinski” option to check your work. In particular, make sure your triangle looks correct after dragging the corner points around and changing the order of the triangle via the slider in the bottom of the window.
Some notes on this problem:
- Draw pictures! The meat of this part of the assignment is figuring out where each triangle’s corners are, and that’s much easier to do with a schematic in front of you.
- The three corner points of the triangle don’t necessarily have to form an equilateral triangle or be parallel to the base or side of the window.
- The only function you should call to draw things in the window is
drawTriangle, which we mentioned earlier in this handout. You don’t need to, say, call thedrawPolarLinefunction from lecture or anything like that. - Don’t forget to call
error()in the case where the order is less than zero. - Our coordinate system uses real numbers. Remember that C++ has separate types for integers and real numbers and be careful not to mix the two up.
![[Pasted image 20240126151529.png]]
Part Two: Human Pyramids
With the exception of the people in the bottom row, each person splits their weight evenly on the two people below them in the pyramid.
![[Pasted image 20240126151719.png]]
In this question, you’ll explore just how much weight that is. Just so we have nice round numbers here, let’s assume that everyone in the pyramid weighs exactly 160 pounds.
Person A at the top of the pyramid has no weight on her back. People B and C each carry half of person A’s weight, so each shoulders 80 pounds.
Now, let’s consider the people in the third row. Focus on person E. That means she’s supporting a net total of 240 pounds.
Not everyone in that third row is feeling the same amount, though; let’s take person D for example.
Person D therefore ends up supporting
- half of person B’s body weight (80 pounds), plus
- half of the weight person B is holding up (40 pounds),
so person D ends up supporting 120 pounds, only half of what E is feeling!
Going deeper in the pyramid, how much weight is person H feeling? Well, person H is supporting
- half of person D’s body weight (80 pounds),
- half of person E’s body weight (80 pounds), plus
- half of the weight person D is holding up (60 pounds), plus
- half of the weight person E is holding up (120) pounds.
There’s a nice, general pattern here that lets us compute how much weight is on each person’s back:
- Each person weighs exactly 160 pounds.
- Each person supports half the body weight of each of the people immediately above them, plus half of the weight that each of those people are supporting.
The question then becomes – given some person in the pyramid, how much weight are they supporting?
Milestone 1: The Initial Implementation
Write a recursive function
1 | double weightOnBackOf(int row, int col, int pyramidHeight); |
that takes as input the row and column number of a person in a human pyramid, along with the number of rows in the pyramid (its height), then returns the total weight on that person’s back.
(row,col) :
![[Pasted image 20240126153026.png]]
If the provided (row, col) position passed into weightOnBackOf is out of bounds you should use the error() function to report an error. For example, if you’re asked to look up position (-1, 0), or position (2, 3), you’d always report an error. Position (3, 1) is in-bounds provided that the pyramid height is at least four, but would be out of bounds if the pyramid height was one, two, or three.
Milestone 1 Requirements
- Add at least one test to
HumanPyramids.cppto cover a case not tested by the other test cases. This is a great opportunity to check that you understand the problem setup.- Implement the
weightOnBackOffunction from HumanPyramids.cpp to report the weight on the back of the indicated person in a human pyramid. Test your solution thoroughly before proceeding, noting that your implementation will be slow if you look deep in the pyramid. Don’t forget to callerror()if the input coordinates are out of bounds!
Some notes on this first milestone:
- Due to the way that the
doubletype works in C++, the values that you get back from your program in large pyramids might contain small rounding errors that make the value close to, but not exactly equal to, the true value (we’re talking about very small errors – less than a part in a thousand). Don’t worry if this happens
Milestone 2: Speeding Things Up
It takes a long time to say how much weight is on the back of the person in row 30, column 15. Why is this?
Think about what happens if we call weightOnBackOf(30, 15). (For simplicity of exposition in this section, we’re going to leave off the height parameter.) This makes two new recursive calls: one to weightOnBackOf(29, 14), and one to weightOnBackOf(29, 15). This first recursive call in turn fires off two more: one to weightOnBackOf(28, 13) and another to weightOnBackOf(28, 14). The second recursive call then calls weightOnBackOf(28, 14) and weightOnBackOf(28, 15).
This means that there’s a redundant call being made to weightOnBackOf(28, 14).For example, calling weightOnBackOf(30, 15) makes over 600,000,000 recursive calls!
There are many techniques for eliminating redundant calls. One common approach is memoization . Intuitively, memoization works by making an auxiliary table keeping track of all the recursive calls that have been made before and what value was returned for each of them. Then, whenever a recursive call is made, the function first checks the table before doing any work. If the the recursive call has already been made in the past, the function just returns that stored value.
Wrapper Function:
1 | Ret functionRec(Arg a, Table& table) { |
Some notes on this milestone:
- One of the bigger questions you’ll need to think through is what type to use to represent the memoization table. There are lots of different options here. Fundamentally, you need something where you can input a (row, col) pair and get back a value. There are lots of containers you can use for this, and lots of ways to represent (row, col) pairs. Some are easier to work with than others. Try things out and see what you find!
- Do not add or remove parameters from the
weightOnBackOffunction. Instead, make it a wrapper around a new function that actually does all the recursive magic. - Make sure that the actual recursive function calls itself and not the wrapper function. If the recursive function calls the wrapper function, it’ll discard the memoization table and start with a new one (do you see why?), which will eliminate all the benefits. More generally, the wrapper should always call the recursive function, and the recursive function should never call the wrapper.
Part Three: What Are YOU Doing?
In conversational English, emphasizing different words in a sentence can change its meaning. For example, the statement
“what are YOU doing?”
places the emphasis on the person being spoken to, with the connotation being “what are you, as opposed to the other people here, doing?” On the other hand, the statement
“what are you DOING?”
puts the emphasis on “doing,” with the connotation that the speaker is exasperated or surprised by the listener’s behavior. Contrast that with
“WHAT ARE YOU DOING?,”
which sounds like someone is shouting, or
“what ARE you doing?,”
which reads as a request for clarification about what the listener happens to be doing at the moment.
All in all, there are sixteen different ways we could emphasize the words in this sentence:
Your task is to write a function:
1 | Set<string> allEmphasesOf(const string& sentence); |
that takes as input a string containing a sentence, then returns a Set containing all the ways of capitalizing the words in that sentence.
The input to this function is a string representing a sentence. It’s probably a lot easier to work not with a single string representing a whole sentence, but with a Vector<string> representing all the pieces of that sentence.
For this purpose, we’ve provided you with
1 | Vector<string> tokenize(const string& sentence); |
which takes as input a sentence, then returns a Vector<string> representing the individual units that make up that sentence.
For example, given the input
1 | Quoth the raven, "Nevermore." |
the tokenize function would return the Vector<string> shown here:
1 | [Quoth] [ ] [the] [ ] [raven] [,] [ ] ["] [Nevermore] [.] ["] |
![[Pasted image 20240126214846.png]]
These strings are formed by considering all possible ways of rendering each word in both upper-case and lower-case, keeping the rest of the input string (spaces, commas, periods, etc.) unchanged.
You should consider a word to be any string that starts with a letter.
######## Part Three Requirements
- Implement the function
allEmphasesOfinWhatAreYouDoing.cppso that it returns a set of all the different ways the words in the input sentence can be capitalized. The non-word strings in the sentence should be included in the output unchanged from the original. - Add at least one test case in to the list of test cases, then test thoroughly.
- After your code passes all the tests, play around with the demo app to have some fun with your program
Some notes on this problem:
- [x] We recommend that your implementation call
tokenizeexactly once to convert the input string into a sequence of tokens; there’s no need to calltokenizerepeatedly. - [x] You should completely ignore the initial capitalization of the words in the input sentence. For example, the result of calling
allEmphasesOfon the strings"Happy birthday!","HAPPY BIRTHDAY!", and"hApPy BiRtHdAy!"should all be the same. - [x] To check if a string represents a word, check if its first character is a letter. Use the
isalphafunction from the header file<cctype>to do this. You don’t need to handle the case where a string has letters in it but not in the first position. - [x] Use the
toUpperCaseandtoLowerCasefunctions from"strlib.h"to convert a string to upper-case or lower-case. Be careful – these functions don’t modify their arguments, and instead return new strings with the case of the letters changed. - [x] There may not be any words in the input sentence. For example, the input sentence might just be a smiley face emoticon (
":-)") or a series of numbers ("867-5309"). - [x] You don’t need to – and in fact, shouldn’t – use the
stringSplitfunction orTokenScannertype to break the original string apart into words. Instead, rely on our handytokenizefunction, which we’ve written for you specifically for this assignment. - [x] Make sure that your solution doesn’t generate the same string more than once. In particular, make sure that your solution doesn’t call
toUpperCaseortoLowerCaseon non-word tokens. If your recursion branches, making one call where the punctuation symbol is converted to upper case and another call where the punctuation symbol is converted to lower case, then it will do a lot of unnecessary work regenerating the same strings twice. (Do you see why?) - [ ] As you saw in Assignment 2, the default C++
stringtype is is pretty bad when it comes to handling non-English characters. As a result, if you feed perfectly reasonable statements like “नमस्ते” or “ٱلسَّلَامُ عَلَيْكُمْ” or “你好” into thetokenizefunction, the results may be completely wrong.
Part Four: Shift Scheduling
You’d like to schedule her hours in a way that gets her to produce the most value.
For each shift(上班伦茨), you have an estimate of how much money the employee would produce if she worked that shift. Ideally, you’d have her work every shift, but alas, that isn’t possible. There are two restrictions. First, the employee has a limited number of hours she’s allowed to work each week. Second, you can’t assign the employee to work concurrent shifts.Given these restrictions, what shifts should you assign to your new hire?
For example, imagine that your new employee is available for twenty hours each week. Here’s the different shifts she could take, as well as how much value (measured in dollars) she’ll produce in each:
Your task is to write a function
1 | Set<Shift> highestValueScheduleFor(const Set<Shift>& shifts, int maxHours); |
that takes as input a Set of all the possible shifts, along with the maximum number of hours the employee is allowed to work for, then returns which shifts the employee should take in order to generate the maximum amount of value.
Here, Shift is a struct containing information about when the shift is (what day of the week it is, when it starts, and when it ends). It’s defined in the header file Shift.h.
Chances are that you won’t need to read any of the fields of this struct, and that instead you’ll want to use these functions from Shift.h:
1 | int lengthOf(const Shift& shift); // Returns the length of a shift. |
Now, let’s talk strategy. We recommend approaching this problem in the following way.
Select, however you’d like, some shift out of shifts. If the employee can’t take this shift, either because it overlaps with a shift she’s already been assigned or because it would exceed her total hour limit, then the only option is to not give the employee that shift.
Otherwise, there are two options: you could either give the employee the shift, or not give the employee the shift. One of these two options will be better than the other, or they’ll be tied for how much value is produced.You won’t know which one is better until you try them out, so (recursively) explore both options and report whichever one leads to more value.
As you’re working on this one, make sure to test thoroughly! Craft smaller examples (say, with between zero and five shifts) and see how your code does.
Think of all the tricksy cases that might arise – long shifts that aren’t worth much, short shifts worth a lot, overlapping shifts that are equally good, etc. – and make sure your code handles those cases well.
######## Problem Four Requirements
- Implement
highestValueScheduleForusing the strategy we outlined above. Select some shift and think about what happens if you assign the employee that shift (if that’s even an option) and what happens if you don’t assign the employee that shift. Take whichever option leads to a better result, and report the set of shifts you’d pick if you chose that route. Use theerror()function to report an error ifnumHours < 0. - Add at least one test using
STUDENT_TEST. Ideally, test something not already covered.
Some notes on this problem:
- [x] You may find it easiest to work on this in stages. First, solve this problem ignoring the restriction that you can’t pick two overlapping shifts. Then, once you have that version working, edit your solution to enforce that you can’t pick overlapping shifts.
- [x] The best schedule might not use up all of the employee’s available hours.
- [x] - It’s fine if the worker has zero available hours – that just means that she’s really busy that week – but if
maxHoursis negative you should callerror()to report an error. - [x] There are two general strategies you can use to explore sets of shifts.
- One option is to generate all possible combinations of shifts, checking only at the end to see whether the shifts overlap with one another or exceed the hourly limits. You should avoid this option – the number of choices of shifts is so huge that this will not finish running in any rea-sonable timeframe.
- The other is to only build up collections of shifts that, at the time they’re built, are known not to exceed the time limit or to contain overlapping shifts. You should favor this approach, since it significantly reduces the number of shift sets to check.
Assignment 4. Recursion to the Rescue!
There are three problems in this assignment. The first one is a warmup, and the next two are the main coding exercises.
- Debugging Practice: The debugger is a powerful tool for helping understand what a program is doing. Learning how to harness it is important to developing as a programmer.
- Matchmaker: We need to partner people up. What’s the best way to do so?
- Disaster Planning: Cities need to plan for natural disasters. Emergency supplies are expensive. What’s the cheapest way to prepare for an emergency?
Part One: Debugging Practice
“What is my program doing, and why is that different than what I intended?”
Part Two: Matchmaker
Background: Perfect Matchings
We can visualize this problem by drawing a circle for each person, then drawing lines connecting pairs of people who would be comfortable working with one another. Here’s an example of what that might look like:
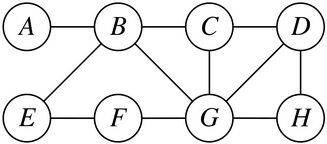
We can encode this diagram as a Map<string, Set<string>>, where each key in the map represents a person and each value represents the set of people they could potentially partner with.
we need to decide which people we will actually partner together.we can do better than all three of the above options. Here’s a better matching:
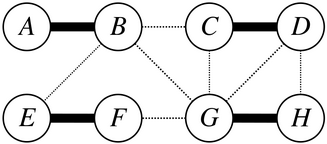
Here, we pair A with B, pair C with D, pair E with F, and pair G with H. Such an arrangement is called a perfect matching.
More generally, a perfect matching is a way to pair people off so that
- each person is assigned a partner,
- no person is assigned two or more partners, and
- each partner pair corresponds to one of the original potential pairings.
However, depending on who wants to work with one another, it’s not always possible to find perfect matchings.Take a minute to convince yourself why a perfect matching isn’t possible in each case.
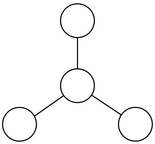
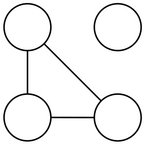
Milestone One: Find Perfect Matchings
Your first task is to write a function
1 | bool hasPerfectMatching(const Map<string, Set<string>>& possibleLinks, |
that takes as input a group of people and the possible links between them, then determines whether a perfect matching exists.If one does, the function should return true and set the matching outparameter to hold one such perfect matching. If one doesn’t, the function should return false, and the contents of matching can be whatever you want them to be.
The Pair type represents a pair of strings, where the order of the strings doesn’t matter.
At each point in time,You’ll find either that everyone is paired off, or that there’s someone who isn’t paired.
######## Milestone One Requirements
- Add at least one
STUDENT_TESTforhasPerfectMatchingtoMatchmaker.cpp. This is a great way to confirm that you understand what the function you’ll be writing is supposed to do. - Implement the
hasPerfectMatchingfunction inMatchmaker.cpp.
Some notes and hints on this problem:
- [x] The links in
possibleLinksare symmetric: if person A is a possible match for person B, then person B is also a possible match for person A. You can assume we’ll never call this function on an input where that isn’t the case. - [x] No person will ever have a possible link to themselves. Each link really does represent a pair of people.
- [x] It’s possible that there’s a person in
possibleLinkswho isn’t linked to anyone, meaning that they aren’t comfortable working with anyone. In that case, there’s no perfect matching. - [x] You may find it easier to solve this problem first by simply getting the return value right, completely ignoring the
matchingoutparameter. Once you’re sure that your code is always producing the right answer, update it so that you actually fill inmatching. Doing so shouldn’t require too much code, and it’s way easier to add this in at the end than it is to debug the whole thing all at once. - [x] You can assume that
matchingis empty when the function is called. - [x] If your function returns
false, the final contents ofmatchingdon’t matter, though we suspect your code will probably leave it blank. - [x] If you need to grab a key out of a
Mapand don’t care which key you get, use the functionmap.firstKey(). To grab a key out of aSet, useset.first(). (Which of these functions, if any, you use in this function are up to you.) - [x] Although the parameters to this function are passed by
constreference, you’re free to make extra copies of the arguments or to set up whatever auxiliary data structures you’d like. If you find you’re “fighting” your code – an operation that seems simple is taking a lot of lines – it might mean that you need to change your data structures. - [ ] You might be tempted to solve this problem by repeatedly taking a person with the most possible partners and then assigning them a partner, or taking the person with the fewest possible partners and picking a partner for them, or something like this. Solutions like these are called greedy algorithms, and while greedy algorithms do work well for some problems, this problem is not one of them. To the best of our knowledge, there is no known greedy algorithm for this problem.
- [x] The very last of the provided tests is a “stress test” designed to check that your algorithmic strategy avoids unnecessary work. Specifically, this test is designed to check whether your code repeatedly generates the same matchings multiple times, or spends time exploring matchings that couldn’t possibly work (say, matchings where a person was intentionally never assigned a partner). If this test never finishes running, or it finishes running only after a very long time, it may mean that the strategy you’ve picked for this problem is intrinsically inefficient. If you run into this, take a look over your code. Make sure each matching you generate is generated exactly once and that you don’t, say, try assigning the same pair of people to each other multiple times.
Background: Maximum-Weight Matchings
Indeed, there are two major shortcomings of this approach.
- If a particular combination of students has a perfect matching, then we can always assign partners to everyone. But there are many cases where this isn’t possible. A simple case would be if there’s an odd number of students, in which case someone necessarily won’t get a partner.
- Up to this point, we’ve been assuming that each pair of people either could be partners, or could not be partners. However, reality is messier than this. There might be a person who could be okay partners with one person, so-so partners with a second, but excellent partners with a third. In that case, we may want to prioritize matching with the third person, since that would be better than the other two options.
Unlike before, though, each one of those possible pairs will have an associated weight representing how good a match they would be.
![[Pasted image 20240203153346.png]]
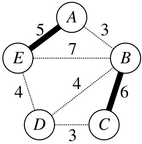
This pairs off A with E and B with C for a total weight of 11. This is the highest weight of any matching here, and so it’s called a maximum-weight matching.
Notice that a maximum-weight matching might not always be a perfect matching.
Your next task is to implement a function
1 | Set<Pair> maximumWeightMatching(const Map<string, Map<string, int>>& possibleLinks); |
that takes as input a weighted preference graph, then returns a matching in that graph with the maximum possible weight.
possibleLinks["A"]["E"] gives the weight of the potential link between A and E (here, 5),
To repeat an important point from above – a maximum weighted matching might not necessarily be a perfect matching. This means that your code must allow for the case where a particular person is not matched with anyone else.
######## Milestone Two Requirements
- Add at least one
STUDENT_TESTformaximumWeightMatchingtoMatchmaker.cpp. This is a great way to confirm that you understand what the function you’ll be writing is supposed to do. - Implement the
maximumWeightMatchingfunction inMatchmaker.cpp. - Test your code thoroughly. Once you’re confident that it works – and no sooner – pull up our bundled demo application and see what sorts of matchings your code can find! Double-click in blank space to create a new person, and add links between people by hovering over a person, clicking in the blue ring around them, and dragging to the person they can pair with.
- [ ] This problem has some similarities to determining whether a perfect matching exists.Previously, you just needed to see whether there was any way to pair everyone off. Now, you need to look across all possible ways of pairing people off and figure out which is the best.Previously, everyone necessarily had to be paired off. Now, the best solution might leave people unpaired. As a result, we do not recommend copying your code for finding perfect matchings and making edits to it.
- [ ] - Watch out for map autoinsertion. If you try to read a weight from
possibleLinksbetween two people who aren’t linked, you’ll see a weight of 0 even though no such link exists. However, there may, independently, be existing links between people of weight 0. - [ ] - It’s possible that there are negative weights in the
possibleLinksmap, indicating two people that would be actively unhappy to be matched with one another. No maximum-weight matching will ever use a negative-weight edge. Depending on how you approach this problem, you may find that you need to add code to account for this case, or you may not. - [ ] - It’s also possible to have a weight of zero, indicating that two people are essentially indifferent about being matched with one another versus not being matched with one another. You may include these edges in your resulting matching, but you aren’t required to do so, since they don’t change the overall weight of the match.